High-Level Approaches for Finding Vulnerabilities
This post is about the approaches I’ve learned for finding vulnerabilities in applications (i.e. software security bugs, not misconfigurations or patch management issues). I’m writing this because it’s something I wish I had when I started. Although this is intended for beginners and isn’t new knowledge, I think more experienced analysts might gain from comparing this approach to their own just like I have gained from others like Brian Chess and Jacob West, Gynvael Coldwind, Malware Unicorn, LiveOverflow, and many more.
Keep in mind that this is a work-in-progress. It’s not supposed to be comprehensive or authoritative, and it’s limited by the knowledge and experience I have in this area.
I’ve split it up into a few sections. I’ll first go over what I think the discovery process is at a high level, and then discuss what I would need to know and perform when looking for security bugs. Finally, I’ll discuss some other thoughts and non-technical lessons learned that don’t fit as neatly in the earlier sections.
What is the vulnerability discovery process?

In some ways, the vulnerability discovery process can be likened to solving puzzles like mazes, jigsaws, or logic grids. One way to think about it abstractly is to see the process as a special kind of maze where:
- You don’t immediately have a birds-eye view of what it looks like.
- A map of it is gradually formed over time through exploration.
- You have multiple starting points and end points but aren’t sure exactly where they are at first.
- The final map will almost never be 100% clear, but sufficient to figure out how to get from point A to B.
If we think about it less abstractly, the process boils down to three steps:
- Enumerate entry points (i.e. ways of interacting with the app).
- Think about insecure states (i.e. vulnerabilities) that an adversary would like to manifest.
- Manipulate the app using the identified entry points to reach the insecure states.
In the context of this process, the maze is the application you’re researching, the map is your mental understanding of it, the starting points are your entry points, and the end points are your insecure states.
Entry points can range from visibly modifiable parameters in the UI to interactions that are more obscure or transparent to the end-user (e.g. IPC). Some of the types of entry points that are more interesting to an adversary or security researcher are:
- Areas of code that are older and haven’t changed much over time (e.g. vestiges of transition from legacy).
- Intersections of development efforts by segmented teams or individuals (e.g. interoperability).
- Debugging or test code that is carried forward into production from the development branch.
- Gaps between APIs invoked by the client vs. those exposed by the server.
- Internal requests that are not intended to be influenced directly by end-users (e.g. IPC vs form fields).
The types of vulnerabilities I think about surfacing can be split into two categories: generic and contextual. Generic vulnerabilities (e.g. RCE, SQLi, XSS, etc.) can be sought across many applications often without knowing much of their business logic, whereas contextual vulnerabilities (e.g. unauthorized asset exposure/tampering) require more knowledge of business logic, trust levels, and trust boundaries.
The rule of thumb I use when prioritizing what to look for is to first focus on what would yield the most impact (i.e. highest reward to an adversary and the most damage to the application’s stakeholders). Lightweight threat models like STRIDE can also be helpful in figuring out what can go wrong.
Let’s take a look at an example web application and then an example desktop application.
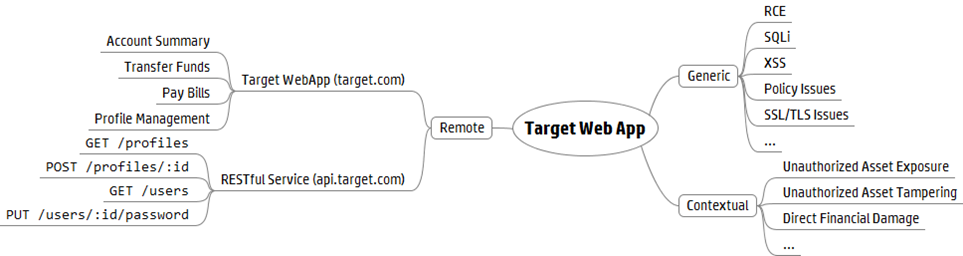
Let’s say this web application is a single-page application (SPA) for a financial portal and we have authenticated access to it, but no server-side source code or binaries. When we are enumerating entry points, we can explore the different features of the site to understand their purpose, see what requests are made in our HTTP proxy, and bring some clarity to our mental map. We can also look at the client-side JavaScript to get a list of the RESTful APIs called by the SPA. A limitation of not having server-side code is that we can’t see the gaps between the APIs called by the SPA and those that are exposed by the server.
The identified entry points can then be manipulated in an attempt to reach the insecure states we’re looking for. When we’re thinking of what vulnerabilities to surface, we should be building a list of test-cases that are appropriate to the application’s technology stack and business logic. If not, we waste time trying test cases that will never work (e.g. trying xp_cmdshell when the back-end uses Postgres) at the expense of not trying test cases that require a deeper understanding of the app (e.g. finding validation gaps in currency parameters of Forex requests).

With desktop applications, the same fundamental process of surfacing vulnerabilities through identified entry points still apply but there are a few differences. Arguably the biggest difference with web applications is that it requires a different set of subject-matter knowledge and methodology for execution. The OWASP Top 10 won’t help as much and hooking up the app to an HTTP proxy to inspect network traffic may not yield the same level of productivity. This is because the entry points are more diverse with the inclusion of local vectors.
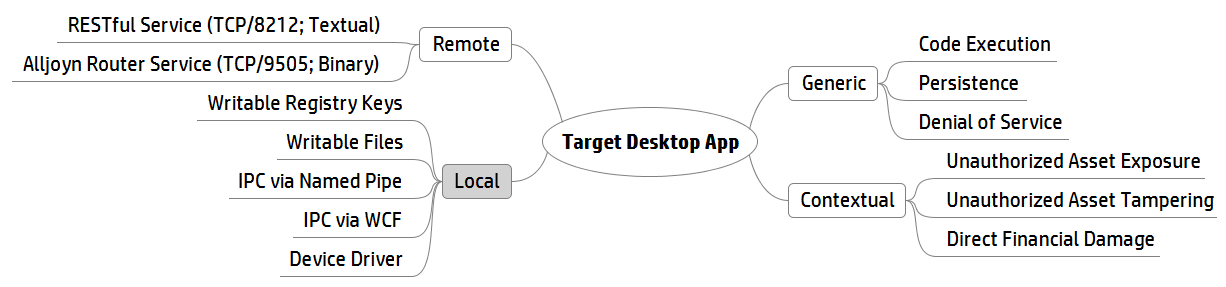
Compared to black-box testing, there is less guesswork involved when you have access to source code. There is less guesswork in finding entry points and less guesswork in figuring out vulnerable code paths and exploitation payloads. Instead of sending payloads through an entry point that may or may not lead to a hypothesized insecure state, you can start from a vulnerable sink and work backwards until an entry point is reached. In a white-box scenario, you become constrained more by the limitations of what you know over the limitations of what you have.
What knowledge is required?
So why are we successful? We put the time in to know that network. We put the time in to know it better than the people who designed it and the people who are securing it. And that’s the bottom line.
The knowledge required for vulnerability research is extensive, changes over time, and can vary depending on the type of application. The domains of knowledge, however, tend to remain the same and can be divided into four:
-
Application Technologies. This embodies the technologies a developer should know to build the target application, including programming languages, system internals, design paradigms/patterns, protocols, frameworks/libraries, and so on. A researcher who has experience programming with the technologies appropriate to their target will usually be more productive and innovative than someone who has a shallow understanding of just the security concerns associated with them.
-
Offensive and Defensive Concepts. These range from foundational security principles to constantly evolving vulnerability classes and mitigations. The combination of offensive and defensive concepts guide researchers toward surfacing vulnerabilities while being able to circumvent exploit mitigations. A solid understanding of application technologies and defensive concepts is what leads to remediation recommendations that are non-generic and actionable.
-
Tools and Methodologies. This is about effectively and efficiently putting concepts into practice. It comes through experience from spending time learning how to use tools and configuring them, optimizing repetitive tasks, and establishing your own workflow. Learning how relevant tools work, how to develop them, and re-purpose them for different use cases is just as important as knowing how to use them.
A process-oriented methodology is more valuable than a tool-oriented methodology. A researcher shouldn’t stop pursuing a lead when a limitation of a tool they’re using has been reached. The bulk of my methodology development has come from reading books and write-ups, hands-on practice, and learning from many mistakes. Courses are usually a good way to get an introduction to topics from experts who know the subject-matter well, but usually aren’t a replacement for the experience gained from hands-on efforts. -
Target Application. Lastly, it’s important to be able to understand the security-oriented aspects of an application better than its developers and maintainers. This is about more than looking at what security-oriented features the application has. This involves getting context about its use cases, enumerating all entry points, and being able to hypothesize vulnerabilities that are appropriate to its business logic and technology stack. The next section details the activities I perform to build knowledge in this area.
The table below illustrates an example of what the required knowledge may look like for researching vulnerabilities in web applications and Windows desktop applications. Keep in mind that the entries in each category are just for illustration purposes and aren’t intended to be exhaustive.
| Web Applications | Desktop Applications |
|---|---|
| Application Technologies | |
 |
 |
| Offensive and Defensive Concepts | |
 |
 |
| Tools and Methodologies | |
 |
 |
| Target Application | |
 |
 |
Thousands of hours, hundreds of mistakes, and countless sleepless nights go into building these domains of knowledge. It’s the active combination and growth of these domains that helps increase the likelihood of finding vulnerabilities. If this section is characterized by what should be known, then the next section is characterized by what should be done.
What activities are performed?
When analyzing an application, I use the four “modes of analysis” below and constantly switch from one mode to another whenever I hit a mental block. It’s not quite a linear or cyclical process. I’m not sure if this model is exhaustive, but it does help me stay on track with coverage.
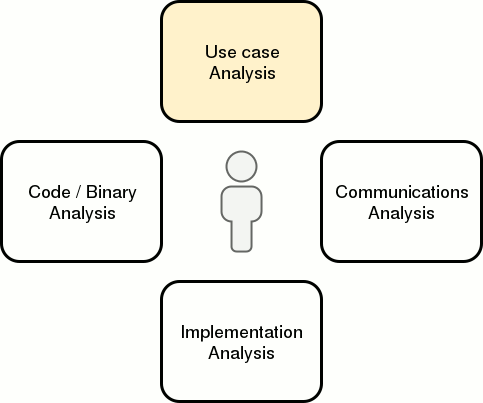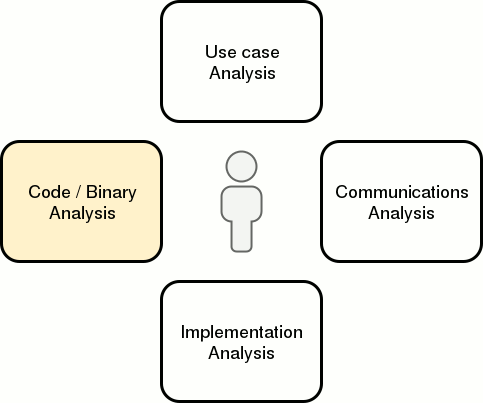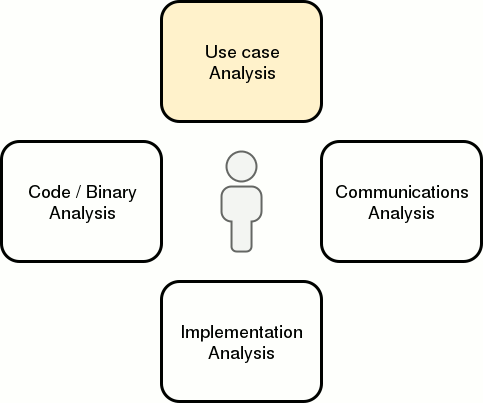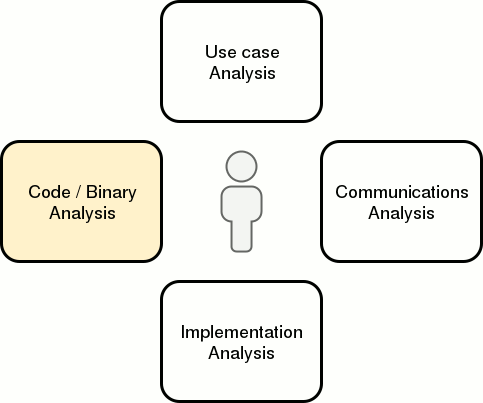
Within each mode are active and passive activities. Active activities require some level of interaction with the application or its environment whereas passive activities do not. That said, the delineation is not always clear. The objective for each activity is to:
- Understand assumptions made about security.
- Hypothesize how to undermine them.
- Attempt to undermine them.
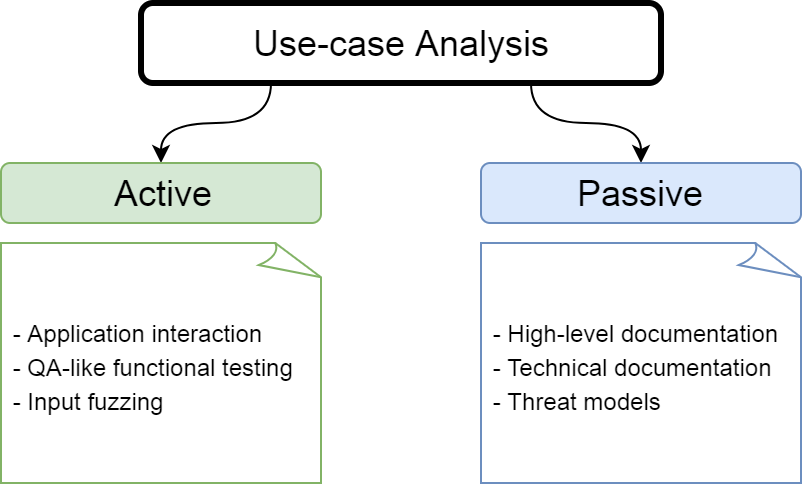
Use case analysis is about understanding what the application does and what purpose it serves. It’s usually the first thing I do when tasked with a new application. Interacting with a working version of the application along with reading some high-level documentation helps solidify my understanding of its features and expected boundaries. This helps me come up with test cases faster. If I have the opportunity to request internal documentation (threat models, developer documentation, etc.), I always try to do so in order to get a more thorough understanding.
This might not be as fun as doing a deep-dive and trying test cases, but it’s saved me a lot of time overall. An example I can talk about is with Oracle Opera where, by reading the user-manual, I was able to quickly find out which database tables stored valuable encrypted data (versus going through them one-by-one).
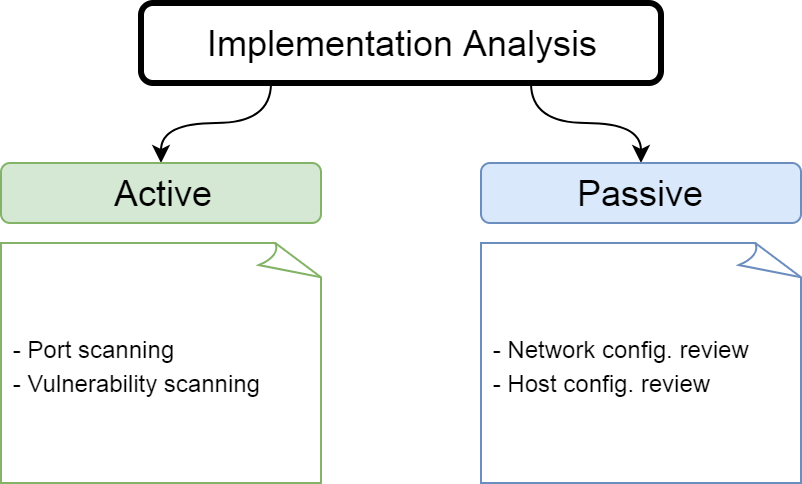
Implementation analysis is about understanding the environment within which the application resides. This may involve reviewing network and host configurations at a passive level, and performing port or vulnerability scans at an active level.
An example of this could be a system service that is installed where the executable has an ACL that allows low-privileged users to modify it (thereby leading to local privilege escalation). Another example could be a web application that has an exposed anonymous FTP server on the same host which could lead to exposure of source code and other sensitive files. These issues are not inherent to the applications themselves, but how they have been implemented in their environments.
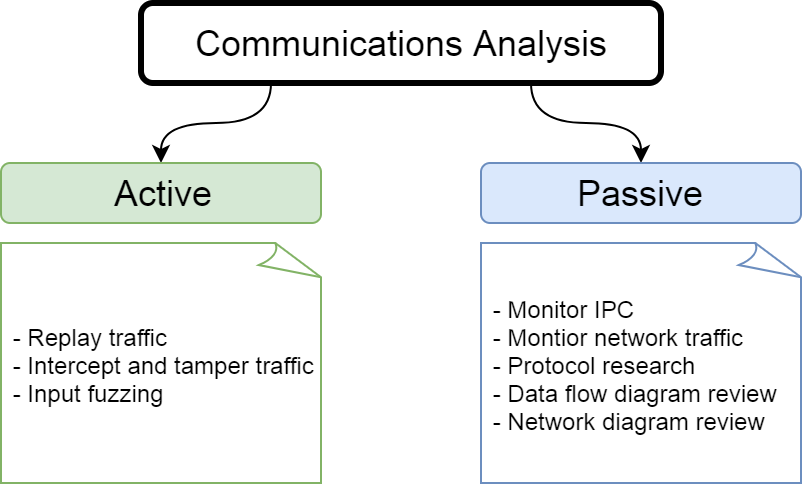
Communications analysis is about understanding what and how the target exchanges information with other processes and systems. Vulnerabilities can be found by monitoring or actively sending crafted requests through different entry points and checking if the responses yield insecure states. Many web application vulnerabilities are found this way. Network and data flow diagrams, if available, are very helpful in seeing the bigger picture.
While an understanding of application-specific communication protocols is required for this mode, an understanding of the application’s internal workings are not. How user-influenced data is being passed and transformed within a system is more or less seen as a black-box in this analysis mode, with the focus on monitoring and sending requests and analyzing the responses that come out.
If we go back to our hypothetical financial portal from earlier, we may want to look at the feature that allows clients to purchase prepaid credit cards in different currencies as a contrived example. Let’s assume that a purchase request accepts the following parameters:
- fromAccount: The account from which money is being withdrawn to purchase the prepaid card.
- fromAmount: The amount of money to place into the card in the currency of fromAccount (e.g. 100).
- cardType: The type of card to purchase (e.g. USD, GBP).
- currencyPair: The currency pair for fromAccount and cardType (e.g. CADUSD, CADGBP).
The first thing we might want to do is send a standard request so that we know what a normal response should look like as a baseline. A request and response to purchase an $82 USD card from a CAD account might look like this:
| Request |
| Response |
We may not know exactly what happened behind the scenes, but it came out ok as indicated by the status attribute. Now if we tweak the fromAmount to something negative, or the fromAccount to someone else’s account, those may return erroneous responses indicating that validation is being performed. If we change the value of currencyPair from CADUSD to CADJPY, we’ll see that the toAmount changes from 82.20 to 8863.68 while the cardType is still USD. We’re able to get more bang for our buck by using a more favourable exchange rate while the desired card type stays the same.
If we have access to back-end code, it would make it easier to know what’s happening to that user input and come up with more thorough test cases that could lead to insecure states with greater precision. Perhaps an additional request parameter that’s not exposed on the client-side could have altered the expected behaviour in a potentially malicious way.
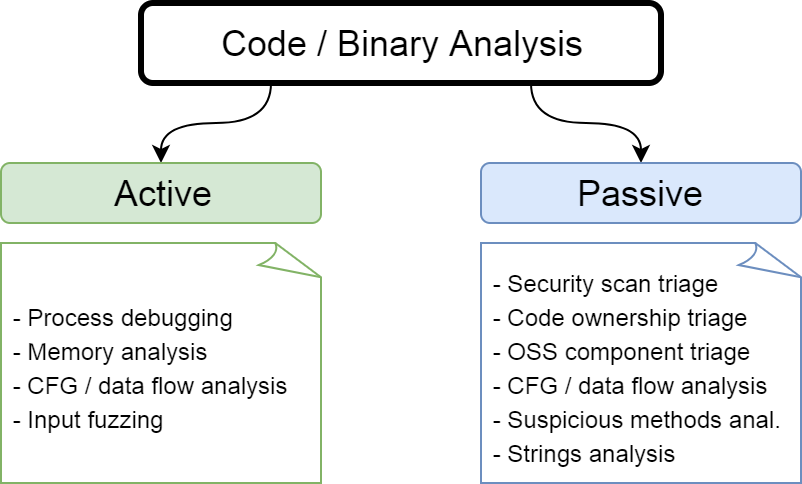
Code and binary analysis is about understanding how user-influenced input is passed and transformed within a target application. To borrow an analogy from Practical Malware Analysis, if the last three analysis modes can be compared to looking at the outside of a body during an autopsy, then this mode is where the dissection begins.
There are a variety of activities that can be performed for static and dynamic analysis. Here are a few:
-
Data flow analysis. This is useful for scouting entry points and understanding how data can flow toward potential insecure states. When I’m stuck trying to get a payload to work in the context of communications analysis, I tweak it in different ways to try get toward that hypothesized insecure state. In comparison with this mode, I can first look into checking whether that insecure state actually exists, and if so, figure out how to craft my payload to get there with greater precision. As mentioned earlier, one of the benefits of this mode is being able to find insecure states and being able to work backwards to craft payloads for corresponding entry points.
Static and dynamic analysis go hand-in-hand here. If you’re looking to go from point A to B, then static analysis is like reading a map, and dynamic analysis is like getting a live overview of traffic and weather conditions. The wide and abstract understanding of an application you get from static analysis is complemented by the more narrow and concrete understanding you get from dynamic analysis. -
Imports analysis. Analyzing imported APIs can give insight into how the application functions and how it interacts with the OS, especially in the absence of greater context. For example, the use of cryptographic functions can indicate that some asset is being protected. You can trace calls to figure out what it’s protecting and whether it’s protected properly. If a process is being created, you can look into determining whether user-input can influence that. Understanding how the software interacts with the OS can give insight on entry points you can use to interact with it (e.g. network listeners, writable files, IOCTL requests).
-
Strings analysis. As with analyzing imports, strings can give some insights into the program’s capabilities. I tend to look for things like debug statements, keys/tokens, and anything that looks suspicious in the sense that it doesn’t fit with how I would expect the program to function. Interesting strings can be traced for their usages and to see if there are code paths reachable from entry points. It’s important to differentiate between strings that are part of the core program and those that are included as part of statically-imported libraries.
-
Security scan triage. Automated source code scanning tools may be helpful in finding generic low-hanging fruit, but virtually useless at finding contextual or design-based vulnerabilities. I don’t typically find this to be the most productive use of my time because of the sheer number of false positives, but if it yields many confirmed vulnerabilities then it could indicate a bigger picture of poor secure coding practices.
-
Dependency analysis. This involves triaging dependencies (e.g. open-source components) for known vulnerabilities that are exploitable, or finding publicly unknown vulnerabilities that could be leveraged within the context of the target application. A modern large application is often built on many external dependencies. A subset of them can have vulnerabilities, and a subset of those vulnerabilities can “bubble-up” to the main application and become exploitable through an entry point. Common examples include Heartbleed, Shellshock, and various Java deserialization vulnerabilities.
-
Repository analysis. If you have access to a code repository, it may help identify areas that would typically be interesting to researchers. Aside from the benefits of having more context than with a binary alone, it becomes easier to find older areas of code that haven’t changed in a long time and areas of code that bridge the development efforts of segmented groups.
Code and binary analysis typically takes longer than the other modes and is arguably more difficult because researchers often need to understand the application and its technologies to nearly the same degree as its developers. In practice, this knowledge can often be distributed among segmented groups of developers while researchers need to understand it holistically to be effective.
I cannot overstate how important it is to have competency in programming for this. A researcher who can program with the technologies of their target application is almost always better equipped to provide more value. On the offensive side, finding vulnerabilities becomes more intuitive and it becomes easier to adapt exploits to multiple environments. On the defensive side, non-generic remediation recommendations can be provided that target the root cause of the vulnerability at the code level.
Similar to the domains of knowledge, actively combining this analysis mode with the others helps makes things click and increases the likelihood of finding vulnerabilities.
Other Thoughts and Lessons Learned
This section goes over some other thoughts worth mentioning that didn’t easily fit in previous sections.
Vulnerability Complexity
Vulnerabilities vary in a spectrum of complexity. On one end, there are trivial vulnerabilities which have intuitive exploit code used in areas that are highly prone to scrutiny (e.g. the classic SQLi authentication bypass). On the other end are the results of unanticipated interactions between system elements that by themselves are neither insecure nor badly engineered, but lead to a vulnerability when chained together (e.g. Chris Domas’ “Memory Sinkhole”). I tend to distinguish between these ends of the spectrum with the respective categories of “first-order vulnerabilities” and “second-order vulnerabilities”, but there could be different ways to describe them.
The modern exploit is not a single shot vulnerability anymore. They tend to be a chain of vulnerabilities that add up to a full-system compromise.
Working in Teams
It is usually helpful to be upfront to your team about what you know and don’t know so that you can (ideally) be delegated tasks in your areas of expertise while being given opportunities to grow in areas of weakness. Pretending and being vague is counterproductive because people who know better will sniff it out easily. If being honest can become political, then maybe it’s not an ideal team to work with. On the other hand, you shouldn’t expect to be spoon-fed everything you need to know. Learning how to learn on your own can help you become self-reliant and help your team’s productivity. If you and your team operate on billable time, the time one takes to teach you might be time they won’t get back to focus on their task.
The composition of a team in a timed project can be a determining factor to the quantity and quality of vulnerabilities found. Depending on the scale and duration of the project, having more analysts could lead to faster results or lead to extra overhead and be counterproductive. A defining characteristic of some of the best project teams I’ve been on is that in addition to having good rapport and communication, we had diverse skill sets that played off each other which enhanced our individual capabilities.
We also delegated parallelizable tasks that had converging outcomes. Here are some examples:
- Bob scouts for entry points and their parameters while Alice looks for vulnerable sinks.
- Alice fleshes out the payload to a vulnerable sink while Bob makes sense of the protocol to the sink’s corresponding entry point.
- Bob reverses structs by analyzing client requests dynamically while Alice contributes by analyzing how they are received statically.
- Bob looks for accessible file shares on a network while Alice sifts through them for valuable information.
Overall, working in teams can increase productivity but it takes some effort and foresight to make that a reality. It’s also important to know when adding members won’t be productive so as to avoid overhead.
Final Notes
Thanks for taking the time to read this if you made it this far. I hope this has taken some of the mystery out of what’s involved when finding vulnerabilities. It’s normal to feel overwhelmed and a sense of impostor syndrome when researching (I don’t think that ever goes away). This is a constant learning process that extends beyond a day job or what any single resource can teach you. I encourage you to try things on your own and learn how others approach this so you can aggregate, combine, and incorporate elements from each into your own approach.
I’d like to thank @spookchop and other unnamed reviewers for their time and contributions. I am always open to more (critical) feedback so please contact me if you have any suggestions.